이번에 소개 할 논문은 Rewarding impact-driven exploration for procedurally-generated environments이라는 논문입니다. 2020 ICLR에 accept된 논문 입니다. (openreview.net/forum?id=rkg-TJBFPB)
RIDE: Rewarding Impact-Driven Exploration for...
Reward agents for taking actions that lead to changes in the environment state.
openreview.net
강화학습에서 주요 문제중 하나는 reward가 부족한 sparse reward problem이고, 이를 해결하기 위한 가장 방법중 하나는 intrinsic reward (exploration bounus)를 추가하는 것입니다. 이 exploration bonus 방법 중 비교적 최근에 나온 방법이면서 직관적이고 효과가 좋은 방법은 Random Network Distillation (RND) 입니다. RND에 대한 소개는 아래 제 포스팅을 참고하시면 될 것 같습니다.
bluediary8.tistory.com/37?category=640398
Exploration by Random Network Distillation
이번에 포스팅 할 논문은 Exploration by Random Network Distillation이라는 논문입니다. OpenAI에서 2018년 10월에 발표한 논문이고 제목에서 알수 있듯이 exploration에 관한 논문입니다. 매우 간단한 아이디..
bluediary8.tistory.com
RND가 나온 이후로 2년이 지났는데요. RND 이후로도 굉장히 많은 방법들이 나오게 되었고, exploration bonus에 관한 논문이 나올때마다 comparison 모델로 RND를 사용하고 있습니다. 그 만큼 RND의 효과가 매우 좋다라는 것을 알 수 있죠. 이번에 소개해 드릴 논문은 RND이후에 나온 논문으로 RND의 단점을 지적하면서 본인들이 제안한 exploration bonus가 매우 효과가 좋다라고 주장하고 있습니다.
논문에서 이야기하는 기존의 intrinsic reward에는 몇가지 문제점이 있습니다.
- Environment가 Deterministic 하다는 strong assumption
- State space가 서로 비슷하다는 strong assumption
- 학습 과정중에 intrinsic reward가 빠르게 감소되는 현상
이중에서도 3번째 단점은 RND에서도 나오고 있습니다. 이러한 한계점을 극복하기 위해 논문의 저자들은 Rewarding Impact-Driven Exploration (RIDE) 기법을 제안하였습니다. RIDE의 컨셉은 environment state가 의미있게 변하는 action을 취하도록 intrinsic reward를 만들겠다라는 것입니다. RIDE가 가지고 있는 특징은 다음과 같습니다.
- Latent state representation을 위한 forward/Inverse dynamics model을 학습시킴
- Intrinsic reward를 predicted state - actual state 대신에, consecutive state representation 사이의 Euclidean distance를 intrinsic reward로 정의 (impact-driven reward)
- 이 reward는 agent가 의미 있는 action 을 취하도록 함
아래 그림은 RIDE의 구조를 시각화 시킨 것입니다. 먼저 Forward 모델은 현재 state와 action 을 통해 다음 state를 예측 하는 모델이며, Inverse 모델은 현재 state와 다음 state를 통해 action 을 예측하는 모델입니다. 그리고 feature공간에서 현재 state와 다음 state의 distacne를 reward로 주게 되는 것입니다. 일반적인 intrinsic reward는 위에서 언급한 바와 같이, predicted state - actual state 로 부여함으로써 예측 못한 action 을 취했 을 때 reward를 부여하도록 하였습니다. 이와 반대로 RIDE는 연속적인 state의 feature의 distance를 reward로 부여하게 됩니다. 즉, 다음 state가 현재 state와 많이 다르면 reward가 많이 부여가 되겠죠. 다시 말해, 다음 state를 현재 state와는 조금 다르게 하는 action 을 취하도록 하겠다라는 것입니다.

기본적으로 RIDE는 다음과 같이 계산할 수 있습니다.
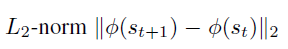
그러나, Agent가 intrinsic reward를 얻기 위해 다시 이전 policy로 돌아가는 것을 막기 위해 episodic state visitation count에 의해 RIDE를 아래와 같이 discount 시킵니다.

여기서 N_ep(State)는 state에 방문한 횟수를 의미함. 즉, 현재 state와 다음 state의 차이가 큰 상황이라고 할지라도, 다음 state가 이전에 방문했던 state면 RIDE reward는 감소 될 것이고, 처음 방문한 state라면 RIDE reward는 커질 것입니다.
RIDE는 이정도 설명이 끝일 정도로 매우 간단한 컨셉을 가지고 있습니다. 물론 RND만큼 간단하지는 않습니다. RND같은 경우에는 Inverse 모델을 만들 필요가 없었기 때문이죠. 이와 반대로 RIDE는 두개의 forward/inverse 모델의 성능에 영향을 받기 때문에, 조금 더 complex하다라는 특징을 가지고 있긴 합니다. 하지만 state와 다음 state의 차이를 reward로 부여하여 agent가 다른 state보도록 유도하는 컨셉은 매우 훌륭한 것 같습니다.
실험결과를 간단히 보여드리고, 마무리 하도록 하겠습니다. 더 많은 실험 결과는 논문을 참고하시면 될 것 같습니다.
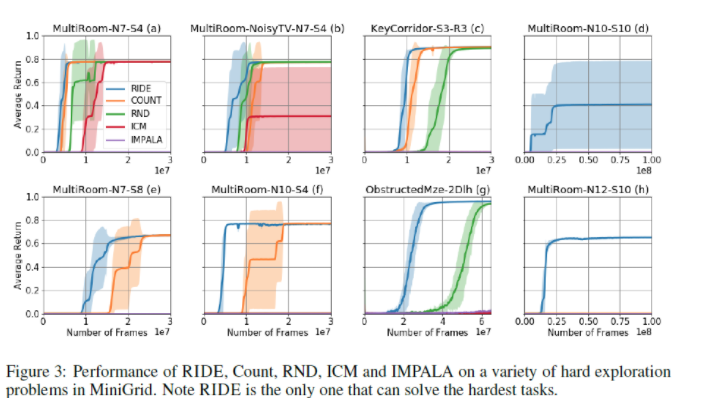

RIDE가 다른 intrinsic reward에 비해 episode가 증가 함에 따라 덜 감소 되는 것을 확인 할 수 있습니다.

'강화학습' 카테고리의 다른 글
| [강화학습 논문 리뷰] NEVER GIVE UP: LEARNING DIRECTED EXPLORATION STRATEGIES (0) | 2020.10.29 |
|---|---|
| [강화학습 논문 리뷰] BEBOLD: EXPLORATION BEYOND THE BOUNDARY OF EXPLORED REGIONS (0) | 2020.10.29 |
| R로하는 강화학습 (DQN) (Keras) (0) | 2018.04.27 |
| R로 하는 강화학습 (DQN) (Base R Code) (0) | 2018.04.23 |
| 예제로 쉽게 알아보는 강화학습 기초(Q-learning, Reinforcement Learning) (5) | 2018.04.07 |


댓글