sample 함수는 R에서 데이터를 복원 추출 또는 비복원 추출을 하게 해주는 함수입니다.
사용법은 간단합니다.
sample(뽑꼬자 하는 후보군, 뽑을 갯수, 확률 정보)
아래와 같이 1부터 10 사이에서 3개를 랜덤하게 선택 할수도 있고
a부터 e문자사이에서 랜덤하게 3개를 선택할 수도 있습니다.
sample(1:10,3)
sample(c("a","b","c","d","e"),3)
당연히 랜덤하게 뽑는거니 아래 캡쳐화면처럼 실행 할 때 마다 결과가 다릅니다.

R에서 sample함수는 기본적으로 비복원 추출입니다.
만약 1부터 10사이에서 100개를 뽑으라고하면 아래 화면처럼 error가 납니다.

복원 추출 option을 주려면 아래와 같이 주시면 됩니다.
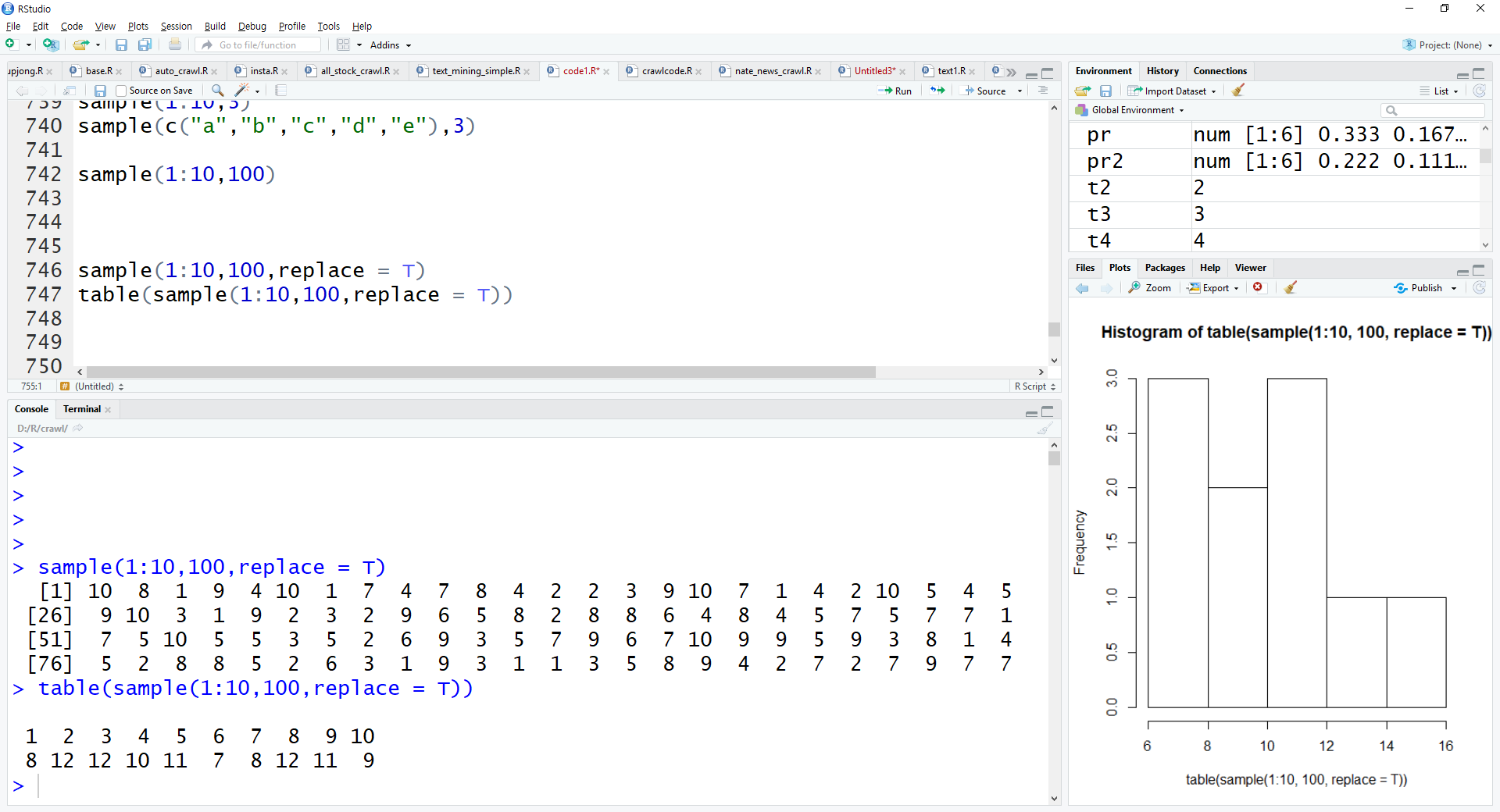
참고로 table 함수는 갯수합계를 구해주는 함수입니다.
sample(1:10,100,replace = T)
table(sample(1:10,100,replace = T))
아래 화면을 보시면 (table 함수의 결과) 1이 8개, 2가 12개 ,,, 10이 9개 뽑힌 것을 볼 수 있습니다.
랜덤하게 추출하다 보니 이 또한, 균일하게 10개씩 뽑히지 않는다라는 것을 알 수 있죠.
아래와 같이 텍스트를 선언하고 랜덤하게 2개를 뽑고, 1000번 복원추출 해보도록 하겠습니다.
x<-c("강아지","고양이","강아지2","고양이2","강아지3","고양이3")
x[sample(1:length(x),2)]
table(sample(x,10000,replace = T))복원 추출 횟수를 늘리니 거의 균일하게 뽑히는 것을 볼 수 있죠.

여기서 강아지가 고양이보다 2배 이상 뽑히도록 해보겠습니다.
sample함수에서 각각의 데이터가 뽑힐 확률을 지정해주시면 됩니다. 기본적으로 각각의 데이터가 뽑힐 확률은 1/n이겠죠?
아래 코드로 확률 값을 기본 1/n 으로 셋팅 후, 확률값을 강제로 두배로 만듭니다. 그리고 scaling을 진행합니다.
scaling을 진행하는 이유는 각각의 데이터가 뽑힐 확률의 합이 1이 되게 하기 위함입니다.
아래 캡쳐화면을 보시면 강아지가 뽑힐확률이 0.22, 고양이가 뽑힐 확률이 0.11로 바뀐 것을 볼 수 있고, 실제로 복원추출해서 확인해보면 두배정도 강아지가 더 많이 뽑힌 것을 확인 할 수 있습니다.
pr<-rep(1/length(x),length(x)) ## 1/6지정
pr[str_detect(x,"강아지")]<-pr[str_detect(x,"강아지")]*2 ## 학률 값 두배 지정
pr2<-pr/sum(pr) ## scaling
pr2
sum(pr2)
table(sample(x,10000,replace = T,prob = pr2))

'R프로그래밍' 카테고리의 다른 글
| R프로그래밍 - 현재 날짜 또는 시간 가져오는 함수 Sys.time / Sys.Date (0) | 2020.07.02 |
|---|---|
| R프로그래밍 - 코드 실행 시키지 않게 유지시키는 Sys.sleep 함수 (0) | 2020.07.02 |
| R프로그래밍 - R에서 함수 내부 변수를 외부에서 사용하는 방법 (0) | 2020.06.30 |
| R 프로그래밍 - plot 저장하기 (해상도 및 크기 조절, multi plot) (0) | 2020.06.29 |
| R프로그래밍 - R에서 자동으로 여러개의 변수 선언하기 (0) | 2020.06.29 |




댓글