머신러닝에서 y값이 특정 클래스 값을 가질때 우리는 분류 모델(classification model)을 적합시킵니다. 분류 모델에서 사용하는 여러가지 성능지표에 대해 알아 보겠습니다.
가장 기본적으로 사용하는게 정확도(accuracy)입니다. 정확도는 사실 구체적으로 설명할 필요도 없이 직관적이고 간단한 지표이죠. R에서는 아래 코드처럼 간단하게 구할수 있습니다. 실제값과 예측값이 같은 수를 전체 관측치 수로 나누어주면 되겠죠.
observed<-c(0,1,1,1,0,0,0,0,1,0)
predicted<-c(0,1,1,1,0,0,0,1,0,0)
sum(observed==predicted)/length(observed)
Accuracy를 기본적으로 가장 많이 사용하기는 하지만, 상황에 따라서 다른 성능지표도 고려할 필요가 있습니다. 예를 들어 클래스 불균형 문제(class imbalanced problem)에서는 다른 성능 지표를 고려 해야합니다. 기본적으로 머신러닝은 이진 분류 문제에서 5:5의 클래스 비율을 가정합니다. 그러나, 실제 데이터의 경우에는 5:5의 비율을 가진 경우가 오히려 훨씬 더 적을 것입니다. 5:5 는 고사하고 6:4도 찾기 쉽지 않습니다. 예를 들어, 보험 사기 예측 문제에서 보험 사기를 차지는 사람과 사기를 치지 않는 사람의 비율이 5:5가 될까요? 최소한 1:9 이상일 것입니다. 또한, 제조 공정 불량 예측 문제에서 불량의 수가 정상의 수가 거의 같을 까요? 불량의 비율은 아무리 높게 잡아도 1%미만입니다. 이러한 경우에는 다양한 문제가 발생하게 되는데, 다른 문제를 거론하기전에 성능지표 부터 바꾸어야 합니다.
불량이 1개 정상이 99개인 데이터가 있다고 가정합시다. 만약 우리가 accruacy를 성능지표로 사용한다면, 모두 정상으로 예측하면 99%의 정확도를 얻게 되고, 아무런 의미 없는 모델이 정확도가 매우 높은(성능이 좋은) 모델로 둔갑하게 됩니다. 이러한 경우 주로 F1-score(F-measure)를 사용합니다.
예측 클래스와 실제 클래스의 표를 아래와 같이 정리했다고 가정해 봅시다.
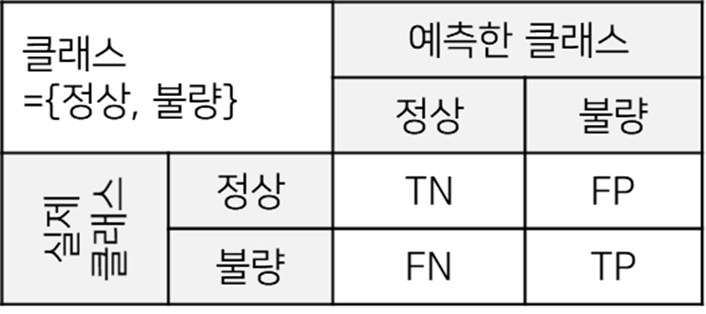
여기서 정밀도, 재현율, 특이도는 다음과 같이 구할 수 있습니다.
정밀도(Precision)=(옳게 분류된 불량 데이터의 수)/(불량으로 예측한 데이터)= TP/(FP+TP)
재현율(Recall)=(옳게 분류된 불량 데이터의 수)/(실제 불량 데이터의 수)=TP/(FN+TP)
특이도(Specificity)=(옳게 분류된 정상 데이터의 수)/(실제 정상 데이터의 수)=TN/(TN+FP)
Class가 극단적으로 불균형인 경우 recall을 중점적으로 보기도 합니다. 불량이 1개라도 나오면 치명적인 영향을 줄 수 있기 때문입니다. 회사의 이익이 불량을 하나라도 놓치면 안되느냐 아니냐에 따라서 중점적으로 바라보는 성능지표가 달라질수 있습니다.
F-measure는 다음과 같이 구할 수 있습니다. Precision과 Recall의 조화 평균입니다. 불량으로 예측해서 잘 맞추는 비율과 실제 불량중에 잘 맞추는 비율을 섞은(?) 느낌이라고 이해할 수 있습니다.

경우에 따라서는 아래와 같이 G-mean을 사용하기도 합니다.

R을 통해서 precision, recall, F-measure는 다음과 같이 구할 수 있습니다.
observed<-c(0,1,1,1,0,0,0,0,1,0,0,0,0,0,0,1)
predicted<-c(0,1,1,1,0,0,0,1,0,0,1,1,0,0,0,0)
(precision<-sum(observed== 1 & predicted ==1)/sum(predicted==1))
(recall<-sum(observed== 1 & predicted ==1)/sum(observed==1))
2*(precision*recall)/(precision+recall) ## F-measure'R프로그래밍' 카테고리의 다른 글
| [R] LASSO, Ridge 적합하기 (0) | 2022.12.11 |
|---|---|
| [R 프로그래밍] SMOTE/BLSMOTE/DBSMOTE 적용하기 (0) | 2022.12.09 |
| R프로그래밍 - 회귀분석에서의 성능 지표 MSE, MAE, MAPE (0) | 2022.05.22 |
| R프로그래밍 - 문자열 대체 함수 gsub [], () <> 없애기 (1) | 2020.07.03 |
| R프로그래밍 - NA, Inf, -Inf 데이터 찾는법 (0) | 2020.07.02 |



댓글