GANs(Generative Adversarial Networks)는 Ian Goodfellow가 처음으로 제안한 genative model로서 최근 3년사이에 origianl GAN에서 발전된 다양한 GAN들이 나왔습니다. (Conditional GAN, InfoGAN, f-GAN, Wessterian GAN, DCGAN, BEGAN, Cycle GAN, DiscoGAN, EBGAN 등등.....)
한국어로 된 GAN자료는 유재준님 블로그(http://jaejunyoo.blogspot.com/2017/01/generative-adversarial-nets-1.html)에 개념적인 설명과 수식적인 설명이 모두 잘 되어 있습니다. 거기에 더불어 제가 GAN을 공부하고 R로 구현하면서 궁금했던 점을 중점적으로 다루어 보겠습니다. (유재준님 블로그를 읽고 제 글을 읽으시면 더 도움이 될것 같습니다.)
우선 GAN은 data를 만들어내는 Generator와 만들어진 data를 평가하는 Discriminator가 서로 대립(Adversarial)적으로 학습해가며 성능을 점차 개선해 나가자는 개념으로 보실 수 있습니다.
Goodfellow가 든 유명한 예제가 있죠.

"지폐위조범(Generator)은 경찰을 최대한 열심히 속이려고 하고 다른 한편에서는 경찰(Discriminator)이 이렇게 위조된 지폐를 진짜와 감별하려고(Classify) 력한다. 이런 경쟁 속에서 두 그룹 모두 속이고 구별하는 서로의 능력이 발전하게 되고 결과적으로는 진짜 지폐와 위조 지폐를 구별할 수 없을 정도(구별할 확률 Pd=0.5)에 이른다는 것"
이처럼 Generator는 Discriminator를 속이게 끔 데이터를 생성하고, Discriminator를 fake Data를 잘 구별하기 위해 학습하게 됩니다. 서로 대립적으로 학습을 해가면서 궁극적으로는 Discriminator를 잘 속이도록(진짜같은 Fake Data를 생성하는) Generator를 학습시키는 것입니다.
D : Discriminator
G : Generator
x : real_data
z : noise
라고 할때,
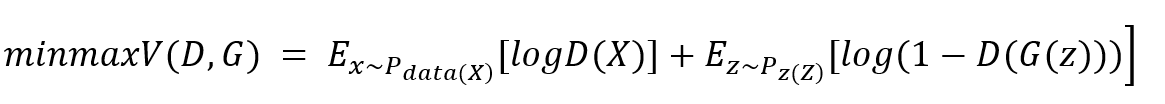
- Discriminator를 학습시킬 때에는 D(x)가 1이 되고 D(G(z))가 0이 되도록 학습시킴
(진짜 데이터를 진짜로 판별하고, 가짜데이터를 가짜로 판별할 수 있도록)
- Generator를 학습시킬 때에는 D(G(z))가 1이 되도록 학습시킴
(가짜 데이터를 discriminator가 구분 못하도록 학습, discriminator를 헷갈리게 하도록)
라고 보시면 됩니다.
MNIST 데이터를 GAN으로 학습시킨다고 하였을 때, Generator와 Discriminator의 구조는 다음과 같습니다.

먼저 G를 보시면, input data는 500개인데, input data수는 mini_batch 수로 설정하기 때문에 크게 신경 쓰지 않으셔도 됩니다. 여기서는 mini_batch 수를 500으로 가져가고, dimension을 64개로 가져갔습니다. 즉, noise z ~ N(0,1,) 를 500 * 64개 생성하신거라고 보시면됩니다. hidden layer의 dimension은 128이고, output은 원래 real_data의 dimension과 맞춰주셔야 합니다. MNIST 데이터가 각 데이터마다 28 * 28 = 784로 이루어져 있으므로, output dimension을 784로 설정 하였습니다. 이렇게 Generator는 noise를 받아 real_data의 dimension에 맞도록 output을 내보내는 거라고 볼 수 있습니다.
Discriminator는 input으로 real 데이터 x를 받을 때가 있고 fake data (G(z))를 받을 때가 있습니다. 바로 위 그림이 real데이터 x를 받는 경우인데, real data를 input으로 넣을 경우 target 값은 1로 설정하여 학습하게 됩니다. 즉, real data를 넣었을 때 output 모두가 1이 나와야 합니다.(진짜 데이터를 진짜로 인식하게 학습)

바로 위 그림이, fake data (G(Z))를 input으로 받아들이는 경우인데, 오른쪽 박스만 보셔도 상관이 없는데, 조금 더 이해하기 쉽도록 G와 D를 이어서 생각하는게 좋을 것 같습니다. 여기서 D(G(z))는 Generator를 학습 시킬 때 사용합니다. (저는 G를 학습시키는데 왜 D가 나오지?? 라는 멍청한 생각을....ㅎ) 이에 대한 설명은 Back Propagation과정에서 좀더 자세히 설명하도록 하겠습니다.
GAN은 D와 G에 대하여 다음과 같은 value function을 minimax problem으로 풀게 됩니다.
D의 입장 : D(x)가 1이고 (진짜 데이터를 1로 구분) D(G(z))가 0일 때 (가짜 데이터를 0으로 구분) V는 최대값
G의 입장 : D(G(z))가 0일 때 (가짜 데이터를 1로 속임) V는 최대값
D의 입장과 G의 입장을 생각 해 보았을때 위 의 Value function이 reasonable하다는 것을 알 수 있고, G와 D가 번갈아가면서 학습되면서 위 문제를 풀게 됩니다.
D와 G가 학습되는 과정을 분포로 보여주는 그림인데 Discriminator가 처음에는 잘 구분을 하지만 가짜 데이터가 점점 진짜 데이터와 비슷한 데이터를 생성하면서 P(g) = P(data) = ½이 되는 것입니다.
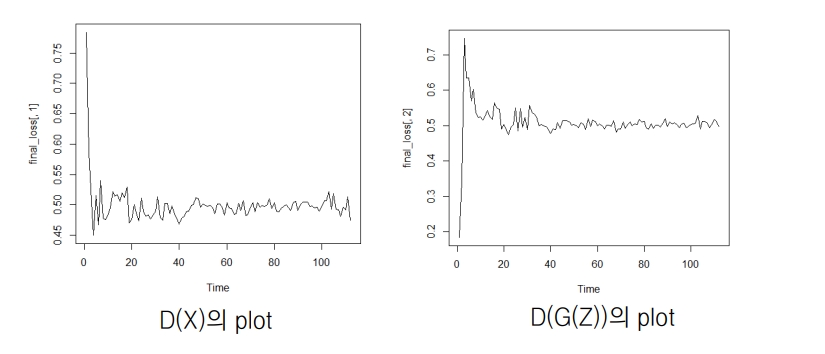
Ian Goodfellow 가 증명하는 것은 크게 두가지 인데, 첫번째로는 위 문제를 푸는 global optimum은 Pg = Pd = 1/2 라는 것과, Neural Network가 위 문제를 잘 풀 수 있다는 것인데, 첫번째 증명만 살짝(?) 언급하고 넘어가도록 하겠습니다. (이론적인 설명은 유재준님 블로그에 설명이 매우매우매우 잘 되어 있습니다 :) )
“Minimax problem은 P(x) = P(G) 에서 global optimum을 갖는다"
Proposition1 : G가 고정된 경우 최적의 D는 다음과 같다
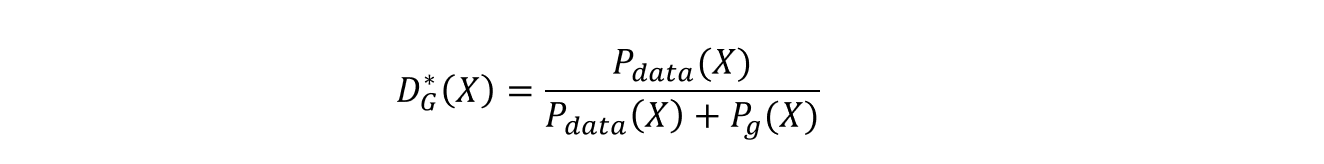
Proof ) Value Function을 다음과 같이 쓸 수 있고,
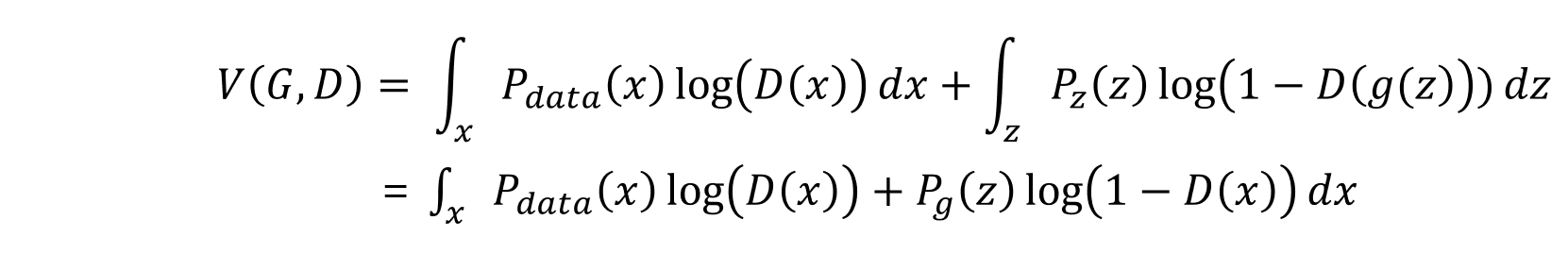
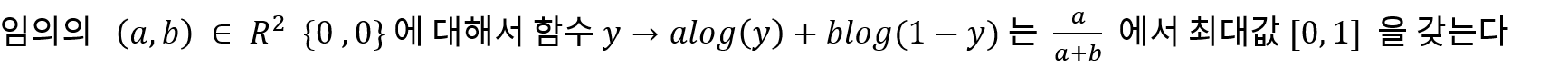
Optimum D가 정해져 있으므로 Value function을 G에 대해 쓰면

Theorem) C(G)의 global minimum은 p(g) = p(data) 인 경우만 달성되며, 이 시점에서 C(G)는 –log(4)
이 Theorem은 KL과 JSD를 이용하여 간단하게 증명이 됩니다.

'딥러닝' 카테고리의 다른 글
| [딥러닝 논문 리뷰] Understanding Deep Learning Requires Rethinking Generalization (0) | 2022.12.10 |
|---|---|
| [GAN 논문 리뷰] RadialGAN (0) | 2022.12.10 |
| 자연어처리(NLP)분야의 다양한 Task와 데이터 (0) | 2020.12.10 |
| [딥러닝 논문 리뷰] DOMAIN GENERALIZATION WITH MIXSTYLE (1) | 2020.10.28 |
| 최근 인공지능 (딥러닝) 적용 사례 (분야) (1) | 2020.06.24 |




댓글