이번에 포스팅할 논문은 Surprise Minimizing Reinforcement Learning(SMiRL)로서 2021년 International Conference on Learning Representations(ICLR)에 구두 발표(Oral)로 Accept된 논문을 통해 제안되었습니다. 인공지능 최고의 Conference에서 Oral 발표로 논문이라는 것은 그만큼 논문의 학술적인 가치가 매우 높다라는 뜻입니다.
이전에 포스팅에서 일반적으로 강화학습의 Exploration을 위한 장치로서 Curiosity를 이용하고 그중 RND가 Baseline으로서 많이 사용된다고 서술하였습니다. 본 논문의 저자들은 Curiosity와 같은 Exploration Method를 Novelty-Seeking Method로 정의하였습니다. 즉, 새로운 곳을 탐험하기 위하여 Agent가 새로운(Novelty) 행동을 하고 State에 대한 Entropy를 높이는 방법론이라는 것이죠. 이는 강화학습 분야에서 Exploration을 위해서는 Novelty-Seeking은 당연한 행동이라고 받아들여져 왔습니다. 본 논문은 이러한 관점에 대해 정면으로 반박하는 논문입니다. 즉, State의 Entropy를 낮추도록 Agent를 학습하자라는 것입니다. State의 Entropy를 낮춘다는 것은 변화가 없는 평온한 상태를 유지하도록 한다는 것입니다. Curiosity와 같은 개념과는 반대되는 개념이라는 것을 알 수 있습니다.
인간이 무인도에 있다고 가정해 봅시다. 무인도에 가만히 있으면 인간은 살아남지 못할 것입니다. 밤이 되면 기온이 떨어져서 추워질 것이고, 비가 오고 눈이 와도 체온은 내려갈 것입니다. 이를 위해 몸을 보호할 옷과 집을 만들어야 합니다. 뿐만 아니라, 생존을 위한 물과 음식 등을 찾으려고 노력합니다. 즉, 무인도에 떨어진 사람(Agent)은 자신의 몸이 변하지 않는 친숙한 상태(Entropy를 낮은 상태로 유지)로 유지하기 위해 행동(Action)을 하게 된다는 것입니다. 아래 그림은 지금 서술한 본 논문의 Motivation을 그림으로 표현한 것입니다.

또한, 인간은 ‘Surprise’로부터 보호하기 위하여 집을 짓고 전기, 가스, 물, 음식 등을 공급받으며 생활합니다. 그래서 논문의 저자들은 이 ‘Surprise’를 최소화하기 위해서는 상태(State)의 Entropy를 낮게 유지해야한다고 주장합니다.

위 그림은 SMiRL의 모델 개념도입니다. 일반적인 강화학습의 개념과 유사하다는 것을 알 수 있습니다. 저자들이 주장하는 것은 State의 Entropy를 낮게 유지시키는 것입니다. 그렇다면 State의 Entropy를 이용하여 Reward를 부여하는 것이 합당할 것입니다. State에 대한 Entropy는 다음과 같이 정의합니다.
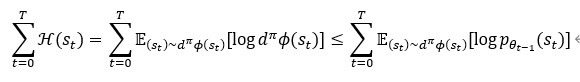
여기서

인 경우에만 위 부등호가 등립으로 성립하고 우측항을 Optimization 하는 문제는 Reward를 다음과 같이 설정하고 최대화하는 것과 같습니다.

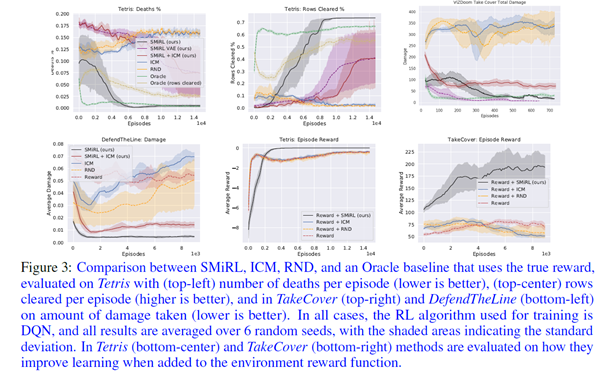
논문에서는 State의 분포를 추정하기 위하여 통계적인 분포를 활용하였고, 복잡한 환경의 경우에는 VAE를 이용하여 State의 분포를 추정하였습니다. 아래 그림과 같이 Tetris, VisDoom, TakeCover등 다양한 환경에서 알고리즘의 성능을 평가하였습니다.

아래 그림의 상단부의 첫번째와 가운데 Plot을 보시면 Tetris에 대한 실험 결과를 확인할 수 있는데, SMiRL이 Oracle(정답)보다 더 좋은 성능을 보이는 것을 알 수 있습니다. 여기서 재밌은 점은 본 서적에서도 소개한 ICM과 RND는 학습이 되면 될수록 Reward가 감소하고 Agent가 죽는 비율이 증가한다는 것을 볼 수 있습니다. Tetris는 블록이 쌓이면 Curiosity가 증가하기 때문에 이러한 결과가 나온 것입니다. [그림 6-24]의 하단부의 가운데와 마지막 Plot을 보시면 SMiRL과 외부 Reward를 결합했을 때의 성능을 볼 수 있는데, 역시나 RND나 ICM에 비해 더 좋은 결과를 보이는 것을 알 수 있습니다.
마찬가지로, 아래 그림을 보시면 Cliff, Treadmill등의 실험 결과를 볼 수 있는데(그래프가 낮아지면 낮아질수록 좋은 것입니다), SMiRL은 제대로 학습이 되는 것을 볼 수 있지만, RND와 ICM은 학습이 되지 않는 것을 확인할 수 있습니다.
그렇다면, 기존에 많이 사용되어온 ICM이나 RND는 과연 잘못된 방법론일까요? 논문의 도입부에서는 자신들이 맞다(True)고 강하게 주장하였습니다. RND나 ICM은 ‘Surprise’를 Maximization하는 방법론이고 SMiRL은 ‘Surprise’를 Minimization하는 방법론이기 때문에 서로 완전이 반대되는 개념입니다. 그렇지만 논문의 중반부에서는 저자들은 두 알고리즘이 서로 상호 보완적이다고 언급합니다. SMiRL에 Intrinsic Reward를 같이 쓰면 ‘Surprise’를 Minimization하는 것을 더욱 잘할 수 있고 효과적으로 Policy를 배울 수 있다고 주장합니다.
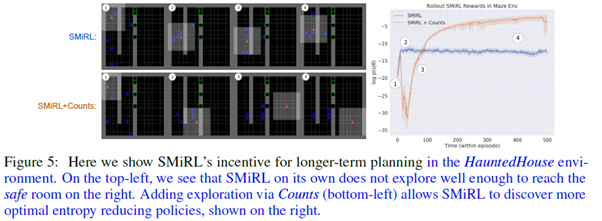
위 그림의 가운데 그림을 보면 SMiRL과 ICM을 결합한 모형이 가장 좋은 성능을 보인 것을 알 수 있으며, 아래 그림을 통해서도 SMiRL보다 SMiRL과 Count(Count-based Exploration)를 결합한 모형이 더 좋은 성능을 보인 것을 확인할 수 있습니다.
결국에는 강화학습 환경에 따라 State의 Entropy를 낮추는 방향으로 학습해야 할지 높이는 방향으로 학습해야 할지 선택해야 한다는 것을 알 수 있습니다.
이번 Chapter에서는 본 서적에서 다룬 알고리즘 외에 최근 강화학습에서 많이 쓰이는 알고리즘들에 대해 다루었습니다. 앞서 언급한 바와 같이 강화학습 분야는 급속도로 발전해오고 있고, 앞으로도 무수히 많이 발전할 것입니다. 본 서적에서 다룬 알고리즘 외에도 수많은 알고리즘과 강화학습 테크닉들이 존재합니다. 연구를 목적으로 공부하시는 분들은 항상 새로운 알고리즘들이 나오는지 살펴볼 필요가 있으며, 현업에서 강화학습을 적용하고자 하시는 분들은 본인이 수행하는 프로젝트의 알고리즘 속도개선이 필요하거나 강화학습 구성요소에 이상이 없는데 수렴이 안될 때 더 좋은 알고리즘을 탐색하고 적용하시면 됩니다.




댓글