선형 회귀 모델의 경우에는 SSE를 최소화 하는 방향으로 회귀 계수를 추정하였습니다. 그렇다면, 당연히 SSE가 작으면 작을수록 좋다라고 이야기 할 수 있습니다. 하지만 SSE의 범위는 0 ~ 무한대 이기 때문에 상대적으로만 비교가 가능합니다. 이를 보완하기 위한 지표가 결정 계수 (R2)입니다.
아래 그림을 보시면 실제 값에서 Y의 평균을 뺀 값은 (실제값 - 예측값) 과 ( 예측값 - y의 평균값) 을 더한 것 과 같다라는 것을 알 수 있습니다. 이를 각각 제곱하여 합하면 맨 아래 식이 도출 됩니다. 각각, SST, SSE, 그리고 SSR로 표기합니다.

사실 일반적으론 위 식이 도출되지는 않습니다만, 아래와 같이 식을 정리 할 수 있는데 여기서 잔차의 합이 0이 되면서 마지막 항이 사라지게 됩니다. 잔차의 합이 0이 되는 이유는 우리가 회귀 계수를 추정 할 때, SSE가 0이 되는 지점을 찾기 위해 회귀 계수로 미분하여 0이 되는 지점을 찾았습니다.

아래 식의 위에를 잘 보시면, 잔차의 합이 0이다 라는 것을 알 수 있습니다. 즉, SSE를 미분하여 0이되는 지점을 찾아 회귀 모델을 만들었고, 이는 결국 잔차의 합이 0이되도록 회귀 계수를 추정했다라는 것을 의미합니다.
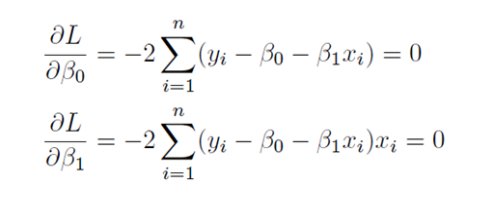
결국에 SST = SSR + SSE의 식이 성립하게 됩니다.

SST는 Y의 총 분산 (변동성)이고 SSE는 회귀 직선으로 설명 불가능한 분산 (변동성) 이며 SSR은 회귀 직선으로 설명 가능한 분산 (변동성) 을 의미합니다. 각각에 대한 자유도는 다음과 같습니다.

SST는 SSR과 SSE로 이루어져 있기 때문에, 우리는 총 분산분에 회귀 직선으로 설명 가능한 분산의 비율을 모델의 성능으로서 사용이 가능합니다. 이를 결정 계수 (R2)라고 하죠. R2의 범위는 0부터 1사이의 값을 가질 수 있습니다.

R2가 0.3이 나왔다고 한다면, 회귀 직선으로 설명 가능 한 총 분산의 비율이 30%다 이렇게 해석을 할 수 있습니다. 보통 0.5 이상은 되어야 잘 설명한다라고 이야기하지만, 사실 실제 데이터의 경우에는 0.5 면 매우 매우 높은 수치입니다. 그만큼 실제 데이터에 대해서 회귀 모델을 적합하기 어렵다는 뜻이겠죠.
'데이터사이언스' 카테고리의 다른 글
| 변수가 증가하면 증가할 수록 결정계수(R2)가 커지는 이유 (0) | 2022.12.14 |
|---|---|
| 테스트 데이터에서 회귀 모델의 결정계수가(R2) 음수가 나오는 이유 (0) | 2022.12.14 |
| 회귀 계수의 의미 (해석 방법) (0) | 2022.12.14 |
| 선형 회귀 계수 추정 방법 (1) | 2022.12.14 |
| 선형 회귀 분석 이란 (Linear regression) (0) | 2022.12.14 |




댓글